[UAS] Klasifikasi Komentar Pada Facebook Dengan Menggunakan Linear Regression
Judul : Klasifikasi Komentar Pada Facebook Dengan Menggunakan Linear Regression
Metode : Klasifikasi dengan algoritma Linear Regression
Tools : Jupyter Notebook
Rumusan
Masalah
Tujuan dan Manfaat Penelitian
Algoritma Linear Regression
Metode : Klasifikasi dengan algoritma Linear Regression
Tools : Jupyter Notebook
Latar Belakang
Media
sosial didefinisikan sebagai kumpulan
perangkat lunak yang memungkinkan individu
maupun komunitas untuk berkumpul,
berbagi, berkomunikasi, dan dalam
kasus tertentu saling berkolaborasi
atau bermain (Boyd & Nasrullah,
2015).Media sosial sangat dibutuhkan masyarakat dunia, karena dapat memperluas
interaksi sosial manusia dengan memanfaatkan teknologi internet dan website,
menciptakan komunikasi dialogis antara banyak audiens (many to many),
membangun personal branding bagi para pengusaha ataupun tokoh
masyarakat, sebagai media komunikasi antara pengusaha ataupun tokoh masyarakat
dengan para pengguna media sosial lainnya.
Menurut
We are social Hootsuite yang dirilis
Juni 2019, sebanyak 3,5 miliar masyarakat dunia sudah menggunakan media
sosial.Termasuk negara Indonesia sendiri.Data Statista 2019 menunjukkan
pengguna internet di Indonesia pada 2018 sebanyak 95,2 juta, tumbuh 13,3% dari
2017 yang sebanyak 84 juta pengguna. Pada tahun selanjutnya pengguna internet
di Indonesia akan semakin meningkat dengan rata-rata pertumbuhan sebesar 10,2%
pada periode 2018-2023. Pada 2019 jumlah pengguna internet di Indonesia
diproyeksikan tumbuh 12,6% dibandingkan 2018, yaitu menjadi 107,2 juta
pengguna. Statista juga menyebutkan kegiatan online yang populer
di Indonesia adalah media sosial dan perpesanan seluler. Adapun jejaring sosial
yang paling banyak digunakan adalah Facebook, dengan jumlah pengguna
mencapai 48% populasi.
“Facebook”
terdiri dari dua frasa dalam Bahasa
Inggris. Face yang berarti muka sedangkan book yang berarti buku.Definisi
secara lengkapnya, Facebook adalah sebuah situs jejaring sosial yang
memungkinkan pengguna dapat saling berinteraksi dengan pengguna lainnya di
seluruh dunia. Frasa “Buku Muka” merupakan prinsip dasar yang membedakan facebook
dengan jejaring sosialnya, yaitu menampilkan seluruh informasi dari pengguna
tersebut.
Jejaring
sosial ini banyak memberikan dampak kepada masyarakat Indonesia, mulai dari
dampak positif maupun dampak negatif.Contoh dari dampak positifnya adalah
masyarakat mudah mendapatkan informasi di dalam negeri maupun luar negeri
secara up to date, dapat membantu pengguna dalam menyebarkan promosi
dagangannya, dapat menjadi wadah untuk mencurahkan isi fikiran dan hati, dan
masih banyak manfaat positif lainnya.
Akan
tetapi, dibalik banyaknya dampak positif banyak pula dampak negatif yang akan
didapatkan melalui jejaring sosial ini.Diantaranya, pengguna akan mudah
mendapatkan postingan yang tidak layak, seperti gambar atau video yang tidak
senonoh tanpa sensor, mudahnya mengkonsumsi berita hoax, dan yang paling
banyak terjadi adalah beberapa public figure yang memiliki pengikut
banyak akan dengan mudahnya mendapatkan komentar yang tidak baik pada
postingannya.Hal ini terjadi karena tidak semua pengguna Facebook bijak
dalam menggunakannya.Sehingga banyak dari pengguna melanggar etika dalam
menggunakan jejaring sosial ini.Komentar yang banyak ditemukan pada Facebook
itu sendiri adalah komentar yang mengandung bullying,
hate speech, SARA, rasis, dan sex harassment.
Oleh
karena itu, penulis ingin membuat sebuah machine learning, dimana dapat
melakukan proses filtering komentar.Kemudian komentar yang disaring akan
diklasifikasikan menjadi komentar positif dan komentar negatif.Untuk komentar
negatif yang didapatkan, akan diklasifikasikan
ke beberapa kelompok.Sehingga, pembaca mengetahui yang mana termasuk komentar bullying,
hate speech, SARA, rasis, dan sex harassment.
Maka dari itu, penulis mengusulkan
menerapkan metode Linear Regression pada penelitian ini, dengan
menggunakan tools jupyter notebook untuk membuat sebuah filtering komentar,
yang diharapkan dapat mengelompokkan jenis-jenis komentar negatif yang terdapat
pada facebook.Penelitian diusulkan dengan judul “Klasifikasi
Komentar Negatif Pada Facebook Dengan Menggunakan Algoritma Linear Regression”.
Rumusan
Masalah
Berdasarkan latar belakang di atas, maka
dapat diidentifikasikan masalah sebagai berikut:
1.
Banyaknya
pengguna Facebook dengan bebas membagikan komentar positif dan negatif
kepada pengguna lain.
2.
Diperlukannya
suatu aplikasi untuk menyaring dan mengklasifikasikan komentar Bahasa Indonesia
pada Facebook.
Tujuan dan Manfaat Penelitian
Tujuan yang ingin dicapai dari penelitian ini adalah
untuk menghasilkan suatu aplikasi penyaring dan klasifikasi komentar Berbahasa
Indonesia dengan menggunakan Algoritma Linear Regression.
Manfaat dari penelitian ini adalah:
1.Tersedianya aplikasi berbasis
web yang dapat digunakan untuk menyaring dan mengklasifikasikan komentar
Berbahasa Indonesia.
2. Dapat menerapkan perhitungan metode Algoritma Linear
Regression pada penelitian klasifikasi komentar Berbahasa Indonesia di Facebook
Tinjauan Pustaka
Pertama,
penelitian berjudul “Klasifikasi Sentyment Analysis
Pada Komentar Peserta Diklat Menggunakan Metode K-Nearest Neighbor”.Penelitian
ini bertujuan untuk memperoleh masukan-masukan berupa komentar dari para
peserta diklat sebagai bahan evaluasi proses pembelajaran serta menggambarkan
tingkat kepuasan peserta terhadap proses diklat.Akan tetapi, pengolahan data
komentar masih dengan proses merekap satu per satu, mulai dari komentar positif
maupun negatif.Maka, penulis menerapkan sentiment analysis untuk proses
Analisa apakah komentar tersebut bersifat positif atau negatif.Metode yang
digunakan dalam penelitian ini adalah metode K-Nearest Nighbor.Dari
hasil pengujian, didapatkan nilai akurasi sebesar 94,23% (Ulfah, Riki, &
Rakhmat, 2019).
Kedua,
penelitian berjudul “Klasifikasi Komentar Spam Pada
Instagram Berbahasa Indonesia Menggunakan K-NN”.Penelitian ini
menggunakan klasifikasi teks untuk menyaring komentar-komentar spam Berbahasa
Indonesia di instagram yang terdapat pada kolom komentar public figure
yang memiliki followers diatas 10juta.Metode klasifikasi yang
diimplementasikan adalah K-Nearest Neighbor.Hasil pengujian masuk dalam
kategori yang sangat baik, yaitu sebesar 87,07% (Antonius & Yuan, 2017).
Ketiga,
penelitian berjudul “Twitter Content
Classification”.Penelitian ini bertujuan untuk melakukan
klasifikasi konten yang ada pada Twitter.Data diperoleh dari sekumpulan
teks yang berasal dari balasan antara pengguna Twitter satu dengan
lainnya (@RT) atau teks yang berasal dari sekumpulan tagar(#).Penelitian ini
akan mengklasifikasikan 6 jenis kategori besar, dan 23 subkategori
terperinci.Dari penelitian ini, akan dihasilkan beberapa konten berupa konten
berita, olahraga, siaran langsung, dan cuaca.Metode yang digunakan adalah grounded
theory (Stephen, 2010).
Keempat, penelitian berjudul “SVM and Na¨ıve Bayes Classification Ensemble Method for
Sentiment Analysis”. Ide utama dari penelitian ini adalah
memperkenalkan dan menguji metode baru dengan dataset yang berasal dari
berbagai media dan memiliki ukuran yang berbeda. Dengan membandingkan metode
dari algoritma SVM dan Na¨ıve Bayes.Yang bertujuan untuk menganalisa sentiment
yang ada pada ulasan film, tweet dan ulasan Amazon.Hasil percobaan menunjukkan
bahwa metode SVM dan Na¨ıve Bayes unggul dalam semua percobaan.Metode
SVM unggul dari (ACC) 0,14% hingga 0,67% dan Na¨ıve Bayes (ACC) dari 2,84%
hingga 6,99% (Konstantinas, Paulius & Gintautas, 2017).
Kelima,
penelitian berjudul “Klasifikasi pesan gangguan pelanggan menggunakan
metode naïve bayes classifier”.Penelitian ini bertujuan untuk melakukan filtering
pesan gangguan pelanggan di suatu daerah.Metode yang digunakan adalah
metode naïve bayees classifier dengan
text mining sebagai pemroses data
awal dari aplikasi.Pengklasifikasian pesan gangguan ini menghasilkan akurasi
dari nilai probabilitas sebesar 95% sedangkan kesalahan sebesar 5% dapat
disebabkan karena banyaknya kata-kata yang mirip pada setiap kelas sehingga
memiliki bobot kata yang berdekatan (Haryono, Prita, Yessy & Andi, 2018).
Metode Penelitian
TF-IDF
Metode TF-IDF merupakan metode
untuk menghitung bobot setiap kata yang paling umum digunakan pada information
retrieval. Metode ini juga terkenal efisien, mudah dan memiliki hasil yang
akurat. Metode ini akan menghitung nilai Term Frequency (TF) dan Inverse
Document Frequency (IDF) pada setiap token (kata) di setiap dokumen dalam
korpus. Metode ini akan menghitung bobot setiap token t di dokumen d dengan
rumus:
Wdt =
tfdt * IDFt
Dimana :
d : dokumen ke-d
t : kata ke-t dari kata kunci
W : bobot dokumen ke-d
terhadap kata ke-t
tf : banyaknya kata yang
dicari pada sebuah dokumen
IDF : Inversed Document
Frequency
Nilai IDF didapatkan dari IDF
: log2 (D/df) dimana :
D : total dokumen
df : banyak dokumen yang
mengandung kata yang dicari
Setelah bobot (W)
masing-masing dokumen diketahui, maka dilakukan proses pengurutan dimana
semakin besar nilai W, semakin besar tingkat similaritas dokumen tersebut
terhadap kata kunci, demikian sebaliknya.
Algoritma Linear Regression
Regresi linear sederhana
adalah hubungan secara linear antara satu variabel independen (X) dengan
variabel dependen (Y). Analisis ini digunakan untuk mengetahui arah hubungan
antara variabel independen dengan variabel dependen apakah positif atau negatif
serta untuk memprediksi nilai dari variabel dependen apabila nilai variabel
independen mengalami kenaikan atau penurunan nilai. Data yang digunakan
biasanya berskala interval atau rasio.Rumus dari dari analisis regresi linear
sederhana adalah sebagai berikut:
Y’ = a
+ bX
Keterangan:
Y= subyek dalam variabel
dependen yang diprediksi
a = harga Y ketika harga X= 0
(harga konstan)
b = angka arah atau koefisien
regresi, yang menunjukkan angka peningkatan ataupun penurunan variabel dependen
yang didasarkan pada perubahan variabel independen. Bila (+) arah garis naik,
dan bila (-) maka arah garis turun.
X = subyek pada variabel
independen yang mempunyai nilai tertentu.
Secara teknik harga b
merupakan tangent dari perbandingan antara panjang garis variabel dependen,
setelah persamaan regresi ditemukan.
untuk hasil, pembahasan, dan kesimpulan dapat dilihat pada link : https://drive.google.com/drive/u/0/my-drive

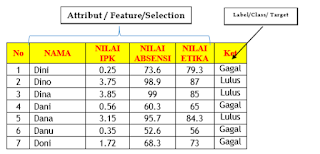

Komentar
Posting Komentar